He realiado una página en Google Plus sobre "Mi granito de Java". Mi intención es que este Blog sea para educación y la página en G+ para compartir novedades, eventos y humor del mundo IT.
Aquellos que quieran seguirla este es el link: https://plus.google.com/u/0/b/101928657082381280272/101928657082381280272
miércoles, 12 de septiembre de 2012
viernes, 7 de septiembre de 2012
Api Reflection
Api Reflection
Java posee un API muy poderosa que no se encuentra en la gran mayoría de los lenguajes. Se trata del API Reflection, que permite comunicarse casi directamente con la máquina virtual de java.
Dicho de otra forma, permite inspeccionar y manipular clases y objetos sin conocer a priori con que objetos estamos trabajando. Este API es utilizada por la gran mayoría de los frameworks como por ejemplo Hibernate o Spring.
La clase Class.
Todos los objetos en java heredan de java.lang.Object y por ello estan dotados del método public final Class getClass(). Este método nos devuelve un objeto java.lang.Class, que va a ser nuestro punto de entrada al API Reflection. En nuestro caso vamos a usar una clase sencilla como ejemplo. La clase Persona, que tiene 4 atributos con sus getters y setters:

Hay diversas formas de obtener el objeto Class. Las más comunes son:

En el primer caso la obtengo de una clase en particular. Si estoy parado en dicha clase también es posible hacer this.getClass(). En el segundo caso obtengo Class a partir de un objeto. Y en el tercer caso obtengo Class a partir del nombre de la clase.
Una vez obtenida la clase es posible acceder a un montón de métodos muy útiles. Los principales son:

Hay varios métodos más que se pueden utilizar. La lista completa esta acá: http://docs.oracle.com/javase/7/docs/api/java/lang/Class.html
Si observamos la lista veremos que varios se repiten pero con la palabra Declared en la firma. Por ejemplo, tenemos getMethods y getDeclaredMethods. La diferencia radica en que el primero obtiene los métodos públicos de la clase y los heredados y el segundo los métodos públicos y privados pero no los heredados.
java.lang.reflect.Field
Field es una clase que representa un atributo de una clase en al API reflection. Tiene muchos metodos interesantes como por ejemplo:
public String getName(): es el nombre del atributo.
public Class getType(): devuelve la clase del atributo.
public int getModifiers(): devuelve los modificadores de un campo representados por un entero que se corresponde con las constantes definidas en la clase java.lang.reflect.Modifier.
public Object get(Object obj): devuelve el valor del atributo.
public void set(Object obj, Object value): setea un valor al atributo.

java.lang.reflect.Method.
Como se habrán imaginado Method tes una clase que representa un método. También tiene varios métodos muy útiles, como por ejemplo:
public String getName(): nombre del método.
public Class[] getParameterTypes(): array con las clases de los parámetros del método.
public Class[] getExceptionTypes(): array con las clases de las excepciones.
public Class getReturnType(): devuelve la clase del valor que devuelve el método.
public Object invoke(Object obj, Object... args): ejecuta el método sobre un objeto, pasándole los parámetros como segundo argumento si es que los necesita. Veremos un ejemplo sobre su uso al final de este post.




Java posee un API muy poderosa que no se encuentra en la gran mayoría de los lenguajes. Se trata del API Reflection, que permite comunicarse casi directamente con la máquina virtual de java.
Dicho de otra forma, permite inspeccionar y manipular clases y objetos sin conocer a priori con que objetos estamos trabajando. Este API es utilizada por la gran mayoría de los frameworks como por ejemplo Hibernate o Spring.
La clase Class.
Todos los objetos en java heredan de java.lang.Object y por ello estan dotados del método public final Class getClass(). Este método nos devuelve un objeto java.lang.Class, que va a ser nuestro punto de entrada al API Reflection. En nuestro caso vamos a usar una clase sencilla como ejemplo. La clase Persona, que tiene 4 atributos con sus getters y setters:
Hay diversas formas de obtener el objeto Class. Las más comunes son:
En el primer caso la obtengo de una clase en particular. Si estoy parado en dicha clase también es posible hacer this.getClass(). En el segundo caso obtengo Class a partir de un objeto. Y en el tercer caso obtengo Class a partir del nombre de la clase.
Una vez obtenida la clase es posible acceder a un montón de métodos muy útiles. Los principales son:
- Field getField(String name): devuelve un campo público de la clase, a partir de su nombre. Si la clase no contiene ningún campo con ese nombre, se comprueban sus superclases recursivamente, y en caso de no encontrar finalmente el campo, se lanzará la excepcion java.lang.NoSuchFieldException.
- Field[] getFields(): devuelve un array con todos los campos públicos de la clase, y de sus superclases.
- Method[] getMethods(): devuelve un array con todos los métodos públicos de la clase, y de sus superclases. También existe el método getMethod que se le puede pedir un método en particular.
- Class[] getInterfaces(): devuelve un array con todos los interfaces que implementa la clase.
- Constructor[] getConstructors(): devuelve un array con todos los constructores públicos.
- También es posible crear un objeto de una clase en particular en tiempo de ejecución gracias al método: public T newInstance().
Nos devuelve un Object que luego podemos castear a la clase correspondiente.
Si observamos la lista veremos que varios se repiten pero con la palabra Declared en la firma. Por ejemplo, tenemos getMethods y getDeclaredMethods. La diferencia radica en que el primero obtiene los métodos públicos de la clase y los heredados y el segundo los métodos públicos y privados pero no los heredados.
java.lang.reflect.Field
Field es una clase que representa un atributo de una clase en al API reflection. Tiene muchos metodos interesantes como por ejemplo:
public String getName(): es el nombre del atributo.
public Class getType(): devuelve la clase del atributo.
public int getModifiers(): devuelve los modificadores de un campo representados por un entero que se corresponde con las constantes definidas en la clase java.lang.reflect.Modifier.
public Object get(Object obj): devuelve el valor del atributo.
public void set(Object obj, Object value): setea un valor al atributo.
java.lang.reflect.Method.
Como se habrán imaginado Method tes una clase que representa un método. También tiene varios métodos muy útiles, como por ejemplo:
public String getName(): nombre del método.
public Class[] getParameterTypes(): array con las clases de los parámetros del método.
public Class[] getExceptionTypes(): array con las clases de las excepciones.
public Class getReturnType(): devuelve la clase del valor que devuelve el método.
public Object invoke(Object obj, Object... args): ejecuta el método sobre un objeto, pasándole los parámetros como segundo argumento si es que los necesita. Veremos un ejemplo sobre su uso al final de este post.
Veremos que diferencia hay entre los metodos getMethods() y getDeclaredMethods().
Como se puede observar getDeclaredMethods() puede ser más util en la mayoría de los casos.
Un ejemplo integrador.
Les voy a mostrar un ejemplo que tuve que hacer para el trabajo. Si bien no es exactamente el mismo, es bastante similar. Resulta que nuestra aplicación enviar por web service ciertos datos para que otra aplicación lo pueda mostrar por una página web. Básicamente envía objetos simples con atributos que sean primitivos o Strings con sus getters y setters.
Esta otra aplicación es un semi enlatado que necesita los datos "escapeados". Esto quiere decir, sin acentos ni caracteres raros, sino con el escape de html.
Nos avisaron de esto muy poco tiempo antes de entregar el producto como no podía ser de otra manera. Por suerte existe una clase en el apache commons lang que nos ayudó mucho ya que tiene un método que convierte un String normal en uno escapeado: StringEscapeUtils.escapeHtml(String s).
El problema es que teniamos que recorrer cada uno de nuestros objetos y escapear cuando sean Strings. Y la realidad es que los seteabamos por toda nuestra aplicación y no lo podiamos hacer en la misma clase (que igual era muy molesto) debido a que también guardabamos el valor en nuestra base de datos y allí no tenía que estar escapeado.
Por ello decidimos utilizar reflaction para que le podamos enviar cualquier objeto y por reflection cambie todos sus strings por strings escapeados:
Y su uso sería el siguiente:
Conclusión.
Este API es muy poderosa y permite realizar muchas cosas que en otro lenguaje sería casi imposible. Pero uno debe evitar a toda costa abusar de la misma. Las personas que hace poco la conocen quieren utilizarla en todos lados y realmente puede hacer mucho lío en el código y en su lectura.
domingo, 14 de agosto de 2011
Introducción a Hibernate
En este post voy a hacer una introducción a Hibernate. Tan sólo un Hola Mundo para que se entiendan los conceptos principales. Luego más adelante haré otras entradas para profundizar un poco más sobre este framework.
Hibernate.
“Hibernate es una herramienta de Mapeo objeto-relacional (ORM) para la plataforma Java (y disponible también para .Net con el nombre de NHibernate) que facilita el mapeo de atributos entre una base de datos relacional tradicional y el modelo de objetos de una aplicación, mediante archivos declarativos (XML) o anotaciones en los beans de las entidades que permiten establecer estas relaciones. Hibernate es software libre, distribuido bajo los términos de la licencia GNU LGPL. “ - Wikipedia.
Hibernate es un framework que agiliza la relación entre la aplicación y la base de datos. De todos los frameworks ORM que he utilizado, sin dudas es el más completo.
Para aprender Hibernte es necesario tener los conocimientos mínimos de SQL y Java. Conocer JDBC es recomendable. Se puede bajar (en principio con bajar Hibernate Core alcanza) de www.hibernate.org

¿Por que usar un framework ORM?
Cuando uno desarrolla una aplicación se dará cuenta que en la gran mayoría de los casos todo termina siendo un conjunto de ABMs (alta, baja, modificación de datos) para luego poder consultarlos. Para ello se utiliza una base de datos, donde existirán muchas tareas repetidas: por cada objeto que quiero persistir debo crear una clase que me permita insertalo, eliminarlo, modificarlo y consultarlo. Salvo aquellas consultas fuera de lo común, el resto es siempre lo mismo. Aquí es donde entra a jugar un rol importante un ORM: con solo configurarlo ya tiene todas esas tareas repetitivas realizadas y el desarrollador solo tendrá que preocuparse por aquellas consultas fuera de lo normal.
¿Como funciona Hibernate?
Básicamente el desarrollador deberá configurar en un archivo XML o mediante annotations donde corresponde un atributo de una clase, con una columna de una tabla. Es una tarea relativamente sencilla donde existen herramientas que lo hacen por nosotros. En principio voy a realizar los ejemplos con archivos xml y luego, en otro post, los haré mediante annotations.
Configuración.
Vamos a hacer un paso a paso para dejar todo listo. Primero vamos a colocar los jars en el proyecto. Aqui van los de hibernate (que vienen en la carpeta lib de la distribución), más el del driver correspondiente a la base de datos que esten utilizando. Yo voy a utilizar DB2. A continuació voy a colocar los jars necesarios. He colocado los de Hibernate + DB2 + MySQL por si alguno la usa.
 Luego vamos a crear una sencilla tabla en la base de datos:
Luego vamos a crear una sencilla tabla en la base de datos:
Para MySQL:
Para DB2:
El siguiente paso es configurar un SessionManager que me permite obtener sesiones y transacciones para trabajar con la base de datos. En este caso haremos uno sencillo, que no sirve para trabajar en producción, pero que nos permite realizar nuestros ejemplos.
Aca les dejo la clase, comentada para que se entienda de donde salen todos los datos.
package configuracion;
import java.util.Properties;
import org.hibernate.HibernateException;
import org.hibernate.MappingException;
import org.hibernate.Session;
import org.hibernate.cfg.Configuration;
public abstract class SessionManager {
public static Session getSession() throws HibernateException{
// Instancia un objeto del tipo Configuration
Configuration config = new Configuration();
// Registra las clases a mapear en la configuracion
registerMappers(config);
// Establece las propiedades de configuracion
config.setProperties(getHibernateProperties() );
// Retorna una sesion de trabajo
return config.buildSessionFactory().openSession();
}
private static Properties getHibernateProperties(){
// Instancia un objeto del tipo Properties.
Properties props = new Properties();
// Establece el driver de conexion dependiente del RDBMS.
//para MySQL seria: props.put("hibernate.connection.driver_class", "com.mysql.jdbc.Driver");
props.put("hibernate.connection.driver_class", "com.ibm.db2.jcc.DB2Driver");
// Establece la url de conexion, donde al final va el nombre de la BD
//para MySQL props.put("hibernate.connection.url", "jdbc:mysql://localhost/testHibernate");
props.put("hibernate.connection.url", "jdbc:db2://localhost:50000/sample");
// Establece el usuario.
props.put("hibernate.connection.username", "db2admin");
// Establece la clave.
props.put("hibernate.connection.password", "db2admin");
// Establece el dialecto a utilizar. Es necesario determinarlo ya que la implementación
// de SQL puede variar con cada motor de base de datos.
// Para MySQL sería: props.put("hibernate.dialect", "org.hibernate.dialect.MySQLDialect");
props.put("hibernate.dialect", "org.hibernate.dialect.DB2Dialect");
// Retorna las propiedades
return props;
}
// Cada clase mapeada deberá aparecer aca.
private static void registerMappers(Configuration config) throws MappingException
{
config.addResource("negocio/Auto.hbm.xml");
}
}
Como verán, he configurado el SessionManager de manera programática. Obviamente lo ideal para un proyecto laboral es hacerlo con archivos de configuracion. Aca hay un ejemplo: http://docs.jboss.org/hibernate/core/3.3/reference/en/html/session-configuration.html
Hasta aquí hemos terminado de confgurar Hibernate. Ahora podemos comenzar a utilizarlo. Para ello, haremos la clase Auto y su correspondiente archivo xml

Y, ahora veremos el archivo auto.hbm.xml. La extensión hbm.xml es por conveción. Este archivo representa la forma de relacionar una clase con una tabla. Existirá un hbm.xml por cada clase que desee mapear. Por lo general, se acostumbra dejar el archivo xml en el mismo paquete de la clase mapeada.
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="negocio.Auto" table="autos">
<id name="id" column="idauto">
<generator class="increment" />
</id>
<property name="marca" />
<property name="modelo" />
</class>
</hibernate-mapping>
Listo, ya tenemos todo para realizar las primeras pruebas. Pero antes voy a explicar que es cada cosa en el xml:
A probar!

Hemos insertado un auto. Tan sencillo como eso, ejecutar el método save.
 Vamos a actualizarlo: ahora lo convertiremos en C4:
Vamos a actualizarlo: ahora lo convertiremos en C4:


Y, por último, eliminaremos el registro:

Algunas últimas aclaraciones:
Hibernate.
“Hibernate es una herramienta de Mapeo objeto-relacional (ORM) para la plataforma Java (y disponible también para .Net con el nombre de NHibernate) que facilita el mapeo de atributos entre una base de datos relacional tradicional y el modelo de objetos de una aplicación, mediante archivos declarativos (XML) o anotaciones en los beans de las entidades que permiten establecer estas relaciones. Hibernate es software libre, distribuido bajo los términos de la licencia GNU LGPL. “ - Wikipedia.
Hibernate es un framework que agiliza la relación entre la aplicación y la base de datos. De todos los frameworks ORM que he utilizado, sin dudas es el más completo.
Para aprender Hibernte es necesario tener los conocimientos mínimos de SQL y Java. Conocer JDBC es recomendable. Se puede bajar (en principio con bajar Hibernate Core alcanza) de www.hibernate.org

¿Por que usar un framework ORM?
Cuando uno desarrolla una aplicación se dará cuenta que en la gran mayoría de los casos todo termina siendo un conjunto de ABMs (alta, baja, modificación de datos) para luego poder consultarlos. Para ello se utiliza una base de datos, donde existirán muchas tareas repetidas: por cada objeto que quiero persistir debo crear una clase que me permita insertalo, eliminarlo, modificarlo y consultarlo. Salvo aquellas consultas fuera de lo común, el resto es siempre lo mismo. Aquí es donde entra a jugar un rol importante un ORM: con solo configurarlo ya tiene todas esas tareas repetitivas realizadas y el desarrollador solo tendrá que preocuparse por aquellas consultas fuera de lo normal.
¿Como funciona Hibernate?
Básicamente el desarrollador deberá configurar en un archivo XML o mediante annotations donde corresponde un atributo de una clase, con una columna de una tabla. Es una tarea relativamente sencilla donde existen herramientas que lo hacen por nosotros. En principio voy a realizar los ejemplos con archivos xml y luego, en otro post, los haré mediante annotations.
Configuración.
Vamos a hacer un paso a paso para dejar todo listo. Primero vamos a colocar los jars en el proyecto. Aqui van los de hibernate (que vienen en la carpeta lib de la distribución), más el del driver correspondiente a la base de datos que esten utilizando. Yo voy a utilizar DB2. A continuació voy a colocar los jars necesarios. He colocado los de Hibernate + DB2 + MySQL por si alguno la usa.
Para MySQL:
CREATE TABLE `autos` (
`IDAUTO` int(10) unsigned NOT NULL auto_increment,
`MARCA` varchar(255) NOT NULL default '',
`MODELO` varchar(255) NOT NULL default '',
PRIMARY KEY (`IDAUTO`)
)
Para DB2:
CREATE TABLE hib.AUTOS (
IDAUTO BIGINT NOT NULL,
MARCA VARCHAR(255),
MODELO VARCHAR(255)
);
CREATE UNIQUE INDEX SQL1108120858221120 ON hib.AUTOS (IDAUTO ASC);
ALTER TABLE hib.AUTOS ADD CONSTRAINT SQL1108128085281980 PRIMARY KEY (IDAUTO);
El siguiente paso es configurar un SessionManager que me permite obtener sesiones y transacciones para trabajar con la base de datos. En este caso haremos uno sencillo, que no sirve para trabajar en producción, pero que nos permite realizar nuestros ejemplos.
Aca les dejo la clase, comentada para que se entienda de donde salen todos los datos.
package configuracion;
import java.util.Properties;
import org.hibernate.HibernateException;
import org.hibernate.MappingException;
import org.hibernate.Session;
import org.hibernate.cfg.Configuration;
public abstract class SessionManager {
public static Session getSession() throws HibernateException{
// Instancia un objeto del tipo Configuration
Configuration config = new Configuration();
// Registra las clases a mapear en la configuracion
registerMappers(config);
// Establece las propiedades de configuracion
config.setProperties(getHibernateProperties() );
// Retorna una sesion de trabajo
return config.buildSessionFactory().openSession();
}
private static Properties getHibernateProperties(){
// Instancia un objeto del tipo Properties.
Properties props = new Properties();
// Establece el driver de conexion dependiente del RDBMS.
//para MySQL seria: props.put("hibernate.connection.driver_class", "com.mysql.jdbc.Driver");
props.put("hibernate.connection.driver_class", "com.ibm.db2.jcc.DB2Driver");
// Establece la url de conexion, donde al final va el nombre de la BD
//para MySQL props.put("hibernate.connection.url", "jdbc:mysql://localhost/testHibernate");
props.put("hibernate.connection.url", "jdbc:db2://localhost:50000/sample");
// Establece el usuario.
props.put("hibernate.connection.username", "db2admin");
// Establece la clave.
props.put("hibernate.connection.password", "db2admin");
// Establece el dialecto a utilizar. Es necesario determinarlo ya que la implementación
// de SQL puede variar con cada motor de base de datos.
// Para MySQL sería: props.put("hibernate.dialect", "org.hibernate.dialect.MySQLDialect");
props.put("hibernate.dialect", "org.hibernate.dialect.DB2Dialect");
// Retorna las propiedades
return props;
}
// Cada clase mapeada deberá aparecer aca.
private static void registerMappers(Configuration config) throws MappingException
{
config.addResource("negocio/Auto.hbm.xml");
}
}
Como verán, he configurado el SessionManager de manera programática. Obviamente lo ideal para un proyecto laboral es hacerlo con archivos de configuracion. Aca hay un ejemplo: http://docs.jboss.org/hibernate/core/3.3/reference/en/html/session-configuration.html
Hasta aquí hemos terminado de confgurar Hibernate. Ahora podemos comenzar a utilizarlo. Para ello, haremos la clase Auto y su correspondiente archivo xml
Y, ahora veremos el archivo auto.hbm.xml. La extensión hbm.xml es por conveción. Este archivo representa la forma de relacionar una clase con una tabla. Existirá un hbm.xml por cada clase que desee mapear. Por lo general, se acostumbra dejar el archivo xml en el mismo paquete de la clase mapeada.
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="negocio.Auto" table="autos">
<id name="id" column="idauto">
<generator class="increment" />
</id>
<property name="marca" />
<property name="modelo" />
</class>
</hibernate-mapping>
Listo, ya tenemos todo para realizar las primeras pruebas. Pero antes voy a explicar que es cada cosa en el xml:
- hibernate-mapping es la raíz del documento y, por ende, todos los tags quedan contenidos dentro de este tag.
- El tag class es general: nombra la clase y la tabla.
- El tag id representa el atributo que se relaciona con la clave primaria. Su atributo name hace referencia a como se llama el id en la clase (en nuestro caso da la casualidad que se llama id) y el atributo column representa la columna en la base de datos.
- El tag property es utilizado para los atributos que no son clave primaria. Sus atributos más importantes son name y column. Si el nombre del atributo coincide con la columna, no es necesario especificar a ambos. Con especificar name es suficiente.
- El tag generator esta contenido dentro de id y representa la forma de generar la clase primaria al insertar un nuevo registro. Puede tomar diversos valores pero los más comunes son:
- increment: para las claves autoincrementales.
- sequence: para los secuenciadores.
- assign: para los casos donde la BD no generá la clave primaria, sino que el objeto es quién la determina.
A probar!
Hemos insertado un auto. Tan sencillo como eso, ejecutar el método save.
Algunas últimas aclaraciones:
- No he hecho consultas mediante Hibernate porque habría que profundizar un poco más y prefiero dejarlo para más adelante.
- Para actualizar un registro es necesario colocarle el id a la clase. En este caso era un Long, por lo que tuve que hacer setId(1L).
- Hibernate elimina por id de manera automática. Por ello, con solo colocarle el id al objeto auto es suficiente. Para eliminaciones más complejas hay que tirar un poco más de código.
martes, 26 de julio de 2011
Log4j
La experiencia indica que el logging forma parte importante del desarrollo de una aplicación. Sobretodo porque nos permite conocer el estado de los objetos en un momento determinado.
Log4j es un framework de Java que se utiliza como herramienta de logging. Muchas veces utilizamos el limitado pero efectivo System.out.printl() para realizar salidas por consola o hacer seguimiento de un error. Si bien a veces con esto alcanza, la realidad es que su alcance es limitado. Hay diversas situaciones en las cuales encuestaríamos algo más completo. Se me ocurre, por ejemplo:
Es simple de usar y entender. Fue hecho en Java; es open source y fue desarrollada en Java por la Apache Software Foundation que permite a los desarrolladores de software elegir la salida y el nivel de granularidad de los mensajes o “logs” (logging) en tiempo de ejecución y no en tiempo de compilación como es comúnmente realizado. Como si fuera poco, es más rápdio que realizar un System.out.print() y le ocupa al sistema menor cantidad de recursos.
La configuración de salida y granularidad de los mensajes es realizada mediante un archivo de configuración externo. Adenás de Java, Log4J ha sido implementado en otros lenguajes como: C, C++, C#, Perl, Python, Ruby y Eiffel.
La página oficial de Log4J es http://logging.apache.org/log4j/ y desde allí debemos bajar los jars necesarios para trabajar en nuestro programa.

Configuración y uso.
Podriamos dividir en dos partes a Log4j. La primer parte consiste en configurarlo. Esto se hace una sola vez y nunca más. En el 99% de los casos no lo tendremos que hacer nosotros, pero es bueno saber como se configura por si alguna vez caemos dentro de ese 1%. La configuración por lo general reside en un archivo de propiedades llamado log4j.properties. Pero debemos tener en cuenta que se puede hacer mediante un achivo xml o programáticamente. Esta última opción no es recomendable ya que se debe tocar código y compilar de nuevo cada vez que se quiere cambiar el nivel del logging.
La segunda parte consiste en saber usarlo. Es la parte más sencilla y con sólo aprender 2 o 3 tips y ya estamos listos.
Primero veremos como se configura y al final de este post veremos como se usa. Si sólo necesitan usarlo pueden ir directamente al final donde se muestran unos ejemplos de uso.
Niveles de prioridad.
Log4j tiene tres components principales para configurar: loggers, appenders y layouts (que los veremos más adelante). Estos tres funcionan juntos para loggear de acuerdo al tipo de mensaje y formato. Cuando escribamos un mensaje para que vaya al log debemos especificar su nivel de prioridad. Por defecto Log4J tiene 6 niveles de prioridad para los mensajes (trace, debug, info, warn, error, fatal). Además existen otros dos niveles extras (all y off).
Niveles de prioridad (De mayor -poco detalle- a menor -mucho detalle-):
Appenders.
En Log4J los mensajes son enviados a una (o varias) salida de destino, lo que se denomina un appender. Existen varios appenders y también podemos crear propios. Típicamente la salida de los mensajes es redirigida a un fichero de texto .log (FileAppender, RollingFileAppender), a un servidor remoto donde almacenar registros (SocketAppender), a una dirección de correo electrónico (SMTPAppender), e incluso en una base de datos (JDBCAppender). Casi nunca es utilizado en un entorno de producción la salida a la consola (ConsoleAppender) ya que perdería gran parte de la utilidad de Log4J.
 No se precupen si no entienden la configuración, de a poco vamos a ver cada punto.
No se precupen si no entienden la configuración, de a poco vamos a ver cada punto.
*Fe de erratas: donde dice No mostrará mensajes por debajo del nivel INFO debería decir No mostrará mensajes por debajo del nivel DEBUG
Los appenders se configuran en el archivo externo.Los appenders que vienen con Log4J se encuentran en el paquete org.apache.log4j. Estos son:
ConsoleAppender
Este appender despliega el log en la consola; tiene las siguientes opciones:
FileAppender
Este appender redirecciona los mensajes de logs hacia un archivo.

RollingFileAppender
Este appender redirecciona los mensajes de logs hacia un archivo y permite definir politicas de rotación para que el archivo no crezca indefinidamente.
DailyRollingFileAppender
Este appender redirecciona los mensajes de logs hacia un archivo y permite definir politicas de rotación basados en fechas.
SocketAppender
Redirecciona los mensajes de logs hacia un servidor remoto de log.
El mensaje de log se almacenará en el servidor remoto sin sufrir alteraciones en los datos (como fecha, tiempo desde que se inicio la aplicación, NDC), exactamente como si hubiese sido guardado localmente.
El SocketAppender no utiliza Layout. Únicamente serializa el objeto LoggingEvent para enviarlo.
Utiliza TCP/IP, consecuentemente si el servidor es accesible el mensaje eventualemente arribará al servidor. Si el servidor remoto está abajo, la petición de log será simplemente rota. Cuando el servidor vuelva a estar disponible la transmisión se reasume transparentemente.Esta reconexión transparente es realizada por un connector thread que periodicamente revisa si existe conexión con el servidor.
Los eventos de logging son automaticamente almacenados en memoria por la implementación nativa de TCP/IP. Esto quiere decir que si la conexión hacia el servidor de logs es lenta y la conexión con los clientes es rápida, los clientes no se ven afectados por la lentitud de la red.
El SocketAppender tiene las siguientes propiedades:
SMTPAppender
Envia un mail con los mensajes de logs, típicamente se utiliza para los niveles ERROR y FATAL.
El número de eventos de log enviados en el mail depende del valor de BufferSize. El SMTPAppender mantiene únicamente el último BifferSize en un buffer cíclico.
JDBCAppender
Este appender redirecciona los mensajes de log hacia una base de datos.
Otros appeders:
SyslogAppender: redirecciona los mensajes de logs sistemas operativos Unix.
NTEventLogAppender: redirecciona los mensajes de logs hacia los logs del sistema de NT.
JMSAppender: serializa los eventos y los transmite como un mensaje JMS tipo ObjectMessage.
Layouts
Es el responsable de dar un formato de presentación a los mensajes. Permite presentar el mensaje con el formato necesario para almacenarlo simplemente en un archivo de texto .log (SimpleLayout y PatternLayout), en una tabla HTML (HTMLLayout), o en un archivo XML (XMLLayout).
Además podemos añadir información extra al mensaje, como la fecha en que se generó, la clase que lo generó, el nivel que posee, etc. Inclusive se pueden crear layouts propios. Basta con heredar de la clase org.apache.log4j.Layout.
Los layouts que vienen con el PI son: DateLayout, HTMLLayout, PatternLayout, SimpleLayout, XMLLayout.
SimpleLayout, como lo indica su nombre, es algo simple: nivel de prioridad, un "-" y el mensaje en cuestión. Por ejemplo: INFO - Hola Mundo!
El más utilizado es PatternLayout ya que permite darnos la libertad de utilizar la creatividad para crear el formato de los mensajes. Para ello, debemos aprender algunos patrones:
Opcionalmete, se puede especificar los márgenes de cada uno:
%20p: espacios que tenrá a la derecha el nivel de prioridad.
%-20p: espacios que tenrá a la izquierda el nivel de prioridad.

Configuración del entorno.
El entorno log4j es completamente configurable programaticamente. Sin embargo, es mucho más flexible configurar log4j usando archivos de configuración . Estos archivos pueden estar escritos en XML o en Java properties (formato key=value).
Veamos un ejemplo, con un archivo properties donde se colocan dos appenders: uno para realizar una salida por consola y otro para que guarde un archivo. Por otro lado, cada appender tiene un nivel de prioridad distinto.
 Como se puede observar en el ejemplo, usarlo es muy sencillo, basta con decirle a Log4j que nuestra clase quiere guardar log mediante la sentencia Logger.getLogger(Clase.class) y listo. Con eso es suficiente para utilizarlo. Si prestan atención cuando se loguea un mensaje, se coloca el nivel de prioridad.
Como se puede observar en el ejemplo, usarlo es muy sencillo, basta con decirle a Log4j que nuestra clase quiere guardar log mediante la sentencia Logger.getLogger(Clase.class) y listo. Con eso es suficiente para utilizarlo. Si prestan atención cuando se loguea un mensaje, se coloca el nivel de prioridad.
Veremos como quedó el archivo que grabó el log con un nivel de prioridad distinto al de la consola:
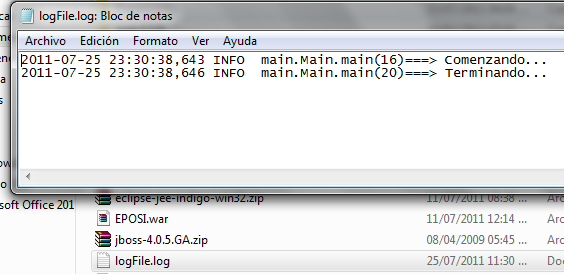
Log4j es un framework de Java que se utiliza como herramienta de logging. Muchas veces utilizamos el limitado pero efectivo System.out.printl() para realizar salidas por consola o hacer seguimiento de un error. Si bien a veces con esto alcanza, la realidad es que su alcance es limitado. Hay diversas situaciones en las cuales encuestaríamos algo más completo. Se me ocurre, por ejemplo:
- Quiero guardar un archivo con las salidas de la consola.
- Quiero ver los mensajes con un formato determinado.
- ¿Que pasa en los casos donde ocurre un error en producción que no se replica en desarrollo? Llenamos de log nuestro código para poder seguirlo! Y cuando lo encontramos, tenemos que volver a sacar todas las líneas que hemos puesto por las distintas clases! Sin contar la cantidad de veces que debo realizar el deploy en producción. Por otro lado, si lleno el código de log, se llena la consola sin sentido, pero sería bueno guardar esas líneas de log por las dudas...entonces ¿No sería bueno tener diversos niveles de log y que se ejecuten las lineas de log que yo quiero con solo modificar el nivel en un archivo de configuración? Estos y otros problemas los puede arreglar Log4j.
Es simple de usar y entender. Fue hecho en Java; es open source y fue desarrollada en Java por la Apache Software Foundation que permite a los desarrolladores de software elegir la salida y el nivel de granularidad de los mensajes o “logs” (logging) en tiempo de ejecución y no en tiempo de compilación como es comúnmente realizado. Como si fuera poco, es más rápdio que realizar un System.out.print() y le ocupa al sistema menor cantidad de recursos.
La configuración de salida y granularidad de los mensajes es realizada mediante un archivo de configuración externo. Adenás de Java, Log4J ha sido implementado en otros lenguajes como: C, C++, C#, Perl, Python, Ruby y Eiffel.
La página oficial de Log4J es http://logging.apache.org/log4j/ y desde allí debemos bajar los jars necesarios para trabajar en nuestro programa.
Configuración y uso.
Podriamos dividir en dos partes a Log4j. La primer parte consiste en configurarlo. Esto se hace una sola vez y nunca más. En el 99% de los casos no lo tendremos que hacer nosotros, pero es bueno saber como se configura por si alguna vez caemos dentro de ese 1%. La configuración por lo general reside en un archivo de propiedades llamado log4j.properties. Pero debemos tener en cuenta que se puede hacer mediante un achivo xml o programáticamente. Esta última opción no es recomendable ya que se debe tocar código y compilar de nuevo cada vez que se quiere cambiar el nivel del logging.
La segunda parte consiste en saber usarlo. Es la parte más sencilla y con sólo aprender 2 o 3 tips y ya estamos listos.
Primero veremos como se configura y al final de este post veremos como se usa. Si sólo necesitan usarlo pueden ir directamente al final donde se muestran unos ejemplos de uso.
Niveles de prioridad.
Log4j tiene tres components principales para configurar: loggers, appenders y layouts (que los veremos más adelante). Estos tres funcionan juntos para loggear de acuerdo al tipo de mensaje y formato. Cuando escribamos un mensaje para que vaya al log debemos especificar su nivel de prioridad. Por defecto Log4J tiene 6 niveles de prioridad para los mensajes (trace, debug, info, warn, error, fatal). Además existen otros dos niveles extras (all y off).
Niveles de prioridad (De mayor -poco detalle- a menor -mucho detalle-):
- FATAL: se utiliza para mensajes críticos del sistema, generalmente después de guardar el mensaje el programa abortará.
- ERROR: se utiliza en mensajes de error de la aplicación que se desea guardar, estos eventos afectan al programa pero lo dejan seguir funcionando, como por ejemplo que algún parámetro de configuración no es correcto y se carga el parámetro por defecto.
- WARN: se utiliza para mensajes de alerta sobre eventos que se desea mantener constancia, pero que no afectan al correcto funcionamiento del programa.
- INFO: se utiliza para mensajes informativos sobre el avance de la aplicación. Estimo que deb ser el más utilizado de todos los niveles.
- DEBUG: se utiliza para escribir mensajes de depuración. Este nivel no debe estar activado cuando la aplicación se encuentre en producción.
- TRACE: se utiliza para mostrar mensajes con un mayor nivel de detalle que debug.
- ALL: este es el nivel de máximo detalle, habilita todos los logs (en general equivale a TRACE).
- OFF: este es el nivel de mínimo detalle, deshabilita todos los logs.
Appenders.
En Log4J los mensajes son enviados a una (o varias) salida de destino, lo que se denomina un appender. Existen varios appenders y también podemos crear propios. Típicamente la salida de los mensajes es redirigida a un fichero de texto .log (FileAppender, RollingFileAppender), a un servidor remoto donde almacenar registros (SocketAppender), a una dirección de correo electrónico (SMTPAppender), e incluso en una base de datos (JDBCAppender). Casi nunca es utilizado en un entorno de producción la salida a la consola (ConsoleAppender) ya que perdería gran parte de la utilidad de Log4J.
*Fe de erratas: donde dice No mostrará mensajes por debajo del nivel INFO debería decir No mostrará mensajes por debajo del nivel DEBUG
Los appenders se configuran en el archivo externo.Los appenders que vienen con Log4J se encuentran en el paquete org.apache.log4j. Estos son:
ConsoleAppender
Este appender despliega el log en la consola; tiene las siguientes opciones:
- Threshold=WARN: Este parámetro establece que el appender no despliega ningún mensaje con prioridad menor a la especificada aquí.
- ImmediateFlush=true: El valor por defecto es true, esto quiere decir que los mensajes de log no son almacenados en un buffer, sino que son enviados directamente al destino.
- Target=System.err: El valor por defecto es System.out. Establece la salida del sistema a ser utilizada.
FileAppender
Este appender redirecciona los mensajes de logs hacia un archivo.
- Threshold=WARN: Este parámetro establece que el appender no despliega ningún mensaje con prioridad menor a la especificada aquí.
- ImmediateFlush=true: El valor por defecto es true, esto quiere decir que los mensajes de log no son almacenadosen un buffer, sino que son enviados directamente al destino.
- File=mylog.txt: Nombre del archivo donde se almacenará el log. Se puede utilizar el nombre de algún property (${nombre_de_la_propiedad}) para especificar el nombre o la ubicación del archivo.
- Append=false: El valor por defecto es true, para que los nuevos mensajes de logs se adicionen al archivo existente.
- Si se especifica false, cuando se inicie la aplicación el archivo de log se sobreescribirá.
RollingFileAppender
Este appender redirecciona los mensajes de logs hacia un archivo y permite definir politicas de rotación para que el archivo no crezca indefinidamente.
- Threshold=WARN: Este parámetro establece que el appender no despliega ningún mensaje con prioridad menor a la especificada aquí.
- ImmediateFlush=true: El valor por defecto es true, esto quiere decir que los mensajes de log no son almacenados en un buffer, sino que son enviados directamente al destino.
- File=mylog.txt: Nombre del archivo donde se almacenará el log. Se puede utilizar el nombre de algún property (${nombre_de_la_propiedad}) para especificar el nombre o la ubicación del archivo.
- Append=false: El valor por defecto es true, para que los nuevos mensajes de logs se adicionen al archivo existente. Si se especifica false, cuando se inicie la aplicación el archivo de log se sobreescribirá.
- MaxFileSize=100KB: Los sufijos pueden ser KB, MB o GB. Rota el archivo de log cuando alcanza el tamaño especificado.
- MaxBackupIndex=2: Mantiene un máximo de 2 (por ejemplo) archivos de respaldo. Borra los archivos anteriores.Si se especifica 0 no se mantiene respaldos.
DailyRollingFileAppender
Este appender redirecciona los mensajes de logs hacia un archivo y permite definir politicas de rotación basados en fechas.
- Threshold=WARN: Este parámetro establece que el appender no despliega ningún mensaje con prioridad menor a la especificada aquí.
- ImmediateFlush=true: El valor por defecto es true, esto quiere decir que los mensajes de log no son almacenados en un buffer, sino que son enviados directamente al destino.
- File=mylog.txt: Nombre del archivo donde se almacenará el log. Se puede utilizar el nombre de algún property (${nombre_del_property}) para especificar el nombre o la ubicación del archivo.
- Append=false: El valor por defecto es true, para que los nuevos mensajes de logs se adicionen al archivo existente.Si se especifica false, cuando se inicie la aplicación el archivo de log se sobreescribirá.
- DatePattern='.'yyyy-ww: Rota el archivo cada semana Se puede especificar que la frecuencia de rotación sea mensual, semanal, diaria, 2 veces al día, cada hora o cada minuto. Este valor no solo especifica la frecuencia de rotación sino el sufijo del archivo de respaldo. Algunos ejemplos de frecuencia de rotación son:
- '.'yyyy-MM: Rota el archivo el primero de cada mes
- '.'yyyy-ww: Rota el archivo al inicio de cada semana
- '.'yyyy-MM-dd: Rota el archivo a la media noche todos los días
- '.'yyyy-MM-dd-a: Rota el archivo a la media noche y al media día, todos los días
- '.'yyyy-MM-dd-HH: Rota el archivo al inicio de cada hora
- '.'yyyy-MM-dd-HH-mm: Rota el archivo al inicio de cada minuto
SocketAppender
Redirecciona los mensajes de logs hacia un servidor remoto de log.
El mensaje de log se almacenará en el servidor remoto sin sufrir alteraciones en los datos (como fecha, tiempo desde que se inicio la aplicación, NDC), exactamente como si hubiese sido guardado localmente.
El SocketAppender no utiliza Layout. Únicamente serializa el objeto LoggingEvent para enviarlo.
Utiliza TCP/IP, consecuentemente si el servidor es accesible el mensaje eventualemente arribará al servidor. Si el servidor remoto está abajo, la petición de log será simplemente rota. Cuando el servidor vuelva a estar disponible la transmisión se reasume transparentemente.Esta reconexión transparente es realizada por un connector thread que periodicamente revisa si existe conexión con el servidor.
Los eventos de logging son automaticamente almacenados en memoria por la implementación nativa de TCP/IP. Esto quiere decir que si la conexión hacia el servidor de logs es lenta y la conexión con los clientes es rápida, los clientes no se ven afectados por la lentitud de la red.
El SocketAppender tiene las siguientes propiedades:
- Threshold=WARN: Este parámetro establece que el appender no despliega ningún mensaje con prioridad menor a la especificada aquí.
- ImmediateFlush=true: El valor por defecto es true, esto quiere decir que los mensajes de log no son almacenados en un buffer, sino que son enviados directamente al destino.
- port=6548: Especifica el puerto por el que se va a comunicar al servidor de logs.
- remoteHost=192.168.10.225: Especifica la máquina donde se encuentra el servidor de logs.
- reconnectionDelay=300: El valor por defecto es de 30000 milisegundos, que corresponden a 30 segundos. Es un valor entero que corresponde al número de milisegundos que va a esperar para volver a intentar conectarse con el servidor cuando se ha perdido comunicación con este.
SMTPAppender
Envia un mail con los mensajes de logs, típicamente se utiliza para los niveles ERROR y FATAL.
El número de eventos de log enviados en el mail depende del valor de BufferSize. El SMTPAppender mantiene únicamente el último BifferSize en un buffer cíclico.
- Threshold=WARN: Este parámetro establece que el appender no despliega ningún mensaje con prioridad menor a la especificada aquí.
- ImmediateFlush=true: El valor por defecto es true, esto quiere decir que los mensajes de log no son almacenados en un buffer, sino que son enviados directamente al destino.
- To=direccion1@dominio.com: Especifica la dirección de correo a donde se enviará el mail.
- From=direccion2@dominio.com: Especifica la dirección de correo desde donde se envia el mail.
- SMTPHost=mail.dominio.com: Especifica el servidor de SMTP que se va a utilizar para enviar el mail.
- Subject=Mensajes de Logs: Especifica el asunto del mail.
- LocationInfo=true: El valor por defecto es false. Envía información acerca de la ubicación donde se generó el evento de log.
- BufferSize=20: El valor por defecto es 512. Representa el número máximo de eventos de logs que serán recolectados antes de enviar el mail.
JDBCAppender
Este appender redirecciona los mensajes de log hacia una base de datos.
- Threshold=WARN: Este parámetro establece que el appender no despliega ningún mensaje con prioridad menor a la especificada aquí.
- ImmediateFlush=true: El valor por defecto es true, esto quiere decir que los mensajes de log no son almacenados en un buffer, sino que son enviados directamente al destino.
- Driver=mm.mysql.Driver: Define el driver a ser utilizado, asegurese de tener la clase en el CLASSPATH.
- URL=jdbc:mysql://localhost/LOG4JDemo: Es la cadena de conexión que se utilizará.
- ser=default: El usuario de la base de datos.
- password=default: La clave para poder ingresar a la base de datos.
- sql=INSERT INTO TABLA (Message) VALUES ('%d - %c - %p - %m'): La instrucción SQL que se utiliza para grabar el mensaje en la base de datos. Si se desea se puede guardar cada valor en columnas separadas,por ejemplo: INSERT INTO JDBCTEST (Date, Logger, Priority, Message) VALUES ('%d', '%c', '%p', '%m').
Otros appeders:
SyslogAppender: redirecciona los mensajes de logs sistemas operativos Unix.
NTEventLogAppender: redirecciona los mensajes de logs hacia los logs del sistema de NT.
JMSAppender: serializa los eventos y los transmite como un mensaje JMS tipo ObjectMessage.
Layouts
Es el responsable de dar un formato de presentación a los mensajes. Permite presentar el mensaje con el formato necesario para almacenarlo simplemente en un archivo de texto .log (SimpleLayout y PatternLayout), en una tabla HTML (HTMLLayout), o en un archivo XML (XMLLayout).
Además podemos añadir información extra al mensaje, como la fecha en que se generó, la clase que lo generó, el nivel que posee, etc. Inclusive se pueden crear layouts propios. Basta con heredar de la clase org.apache.log4j.Layout.
Los layouts que vienen con el PI son: DateLayout, HTMLLayout, PatternLayout, SimpleLayout, XMLLayout.
SimpleLayout, como lo indica su nombre, es algo simple: nivel de prioridad, un "-" y el mensaje en cuestión. Por ejemplo: INFO - Hola Mundo!
El más utilizado es PatternLayout ya que permite darnos la libertad de utilizar la creatividad para crear el formato de los mensajes. Para ello, debemos aprender algunos patrones:
- %m: muestra el mensaje.
- %p: muestra el nivel de prioridad.
- %r: muestra los milisegundos desde que comenzo la aplicación hasta el evento que se logueó.
- %t: muestra el nombre del thread que loguel el evento.
- %x: muestra el NDC del thread que loguel el evento.
- %n: deja un renglón, con lo cual nos olvidamos de "\n" o "\r\n".
- %c: categoría del evento que figura en la configuración.
- %%: muestra un signo de porcentaje.
- %d: muestra la fecha del vento, que se le puede dar un formato determinado, por ejemplo %d{HH:mm:ss,SSS} o %d{dd MMM yyyy HH:mm:ss,SSS}.
- %C: muestra el nombre de la clase que logueo el evento.
- %M: muestra el método de la clase que logueo el evento.
- %L: muestra el número de línea donde se logueo el evento.
Opcionalmete, se puede especificar los márgenes de cada uno:
- Se utiliza el signo menos (-), seguido de un entero para el margen izquierdo.
- Se utiliza un entero para el margen derecho.
- Se utiliza un punto (.) con un entero para el ancho mínimo.
%20p: espacios que tenrá a la derecha el nivel de prioridad.
%-20p: espacios que tenrá a la izquierda el nivel de prioridad.
Configuración del entorno.
El entorno log4j es completamente configurable programaticamente. Sin embargo, es mucho más flexible configurar log4j usando archivos de configuración . Estos archivos pueden estar escritos en XML o en Java properties (formato key=value).
Veamos un ejemplo, con un archivo properties donde se colocan dos appenders: uno para realizar una salida por consola y otro para que guarde un archivo. Por otro lado, cada appender tiene un nivel de prioridad distinto.
log4j.rootCategory= miArchivo, miConsola
# Indica alias para las salidas de log, podemos tener varias
log4j.appender.miArchivo=org.apache.log4j.FileAppender
# Appender miArchivo (lugar donde se envian los mensajes) es un archivo
log4j.appender.miArchivo.Threshold=INFO
# No mostrará mensajes por debajo del nivel INFO
log4j.appender.miArchivo.ImmediateFlush=true
# Se vuelca el mensaje inmediatamente en el appender
log4j.appender.miArchivo.file=C:/Users/Admin/Documents/Java/logFile.log
# Archivo (appender)
log4j.appender.miArchivo.layout=org.apache.log4j.PatternLayout
# Tipo de diseño de los mensajes
log4j.appender.miArchivo.layout.ConversionPattern=%d %-5p %C.%M(%L)===> %m%n
# Diseño
log4j.appender.miArchivo.append=false
# No añade, borra el contenido anterior
log4j.appender.miConsola=org.apache.log4j.ConsoleAppender
# Appender de miConsola
log4j.appender.miConsola.Threshold=DEBUG
# No mostrará mensajes por debajo del nivel INFO
log4j.appender.miConsola.layout=org.apache.log4j.PatternLayout
# miConsola utiliza PatternLayout
log4j.appender.miConsola.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
# Diseño
# Indica alias para las salidas de log, podemos tener varias
log4j.appender.miArchivo=org.apache.log4j.FileAppender
# Appender miArchivo (lugar donde se envian los mensajes) es un archivo
log4j.appender.miArchivo.Threshold=INFO
# No mostrará mensajes por debajo del nivel INFO
log4j.appender.miArchivo.ImmediateFlush=true
# Se vuelca el mensaje inmediatamente en el appender
log4j.appender.miArchivo.file=C:/Users/Admin/Documents/Java/logFile.log
# Archivo (appender)
log4j.appender.miArchivo.layout=org.apache.log4j.PatternLayout
# Tipo de diseño de los mensajes
log4j.appender.miArchivo.layout.ConversionPattern=%d %-5p %C.%M(%L)===> %m%n
# Diseño
log4j.appender.miArchivo.append=false
# No añade, borra el contenido anterior
log4j.appender.miConsola=org.apache.log4j.ConsoleAppender
# Appender de miConsola
log4j.appender.miConsola.Threshold=DEBUG
# No mostrará mensajes por debajo del nivel INFO
log4j.appender.miConsola.layout=org.apache.log4j.PatternLayout
# miConsola utiliza PatternLayout
log4j.appender.miConsola.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
# Diseño
Veremos como quedó el archivo que grabó el log con un nivel de prioridad distinto al de la consola:
jueves, 14 de julio de 2011
Spring Core
Continuando con el post anterior de introducción a Spring, que se puede ver en http://migranitodejava.blogspot.com/2011/06/introduccion-spring.html, vamos a profundizar algunos temas.
Creando Beans.
En Spring hay diversas formas de crear un bean. En el ejemplo de la introducción a Spring vimos una opción donde colocábamos la ruta del xml de configuración:
ApplicationContext respuesta =
new FileSystemXmlApplicationContext("C:/Users/max/eclipse workspace/spring.xml");
Esta forma de crear beans esta bien para un ejemplo o aplicaciones muy chicas, pero es poco práctico para el resto de los casos. Spring nos brinda formas alternativas a FileSystemXmlApplicationContext y las más utilizadas son:
ClassPathXmlApplicationContext: busca el xml en el classpath, para mi gusto es la mejor opción.
XmlWebApplicationContext: el xml se encuentra en un contexto de una aplicación web.
Ciclo de vida de un bean.
En Spring la vida de un objeto difiere de la forma tradicional: existen más oportunidades para aprovechar en la creación o destrucción de un bean. Las distintas etapas son:

Y agregamos lo siguiente al xml:

Inyección por constructores.
Es posible instanciar objetos con un constructor distinto al vacío. Para ello existe un tag llamado <constructor-arg> que posee dos atributos importantes: ref y value. Por ejemplo, si tenemos un constructor que recibe un int podriamos hacer lo siguiente:
<constructor-arg value=”100” />
Pero si se recibe un objeto compuesto se deberá usar el atributo ref que hace referencia a otro bean de Spring y se lo llama por su id:
<constructor-arg ref=”persona” />
Veamos un ejemplo:
 Y el xml:
Y el xml:

Entonces …¿conviene inyectar por constructor o por setter?
Es muy útil la inyección por constructor por varios motivos. Primero, a diferencia de la mayoría de frameworks que nos obligan a que casi todas nuestras clases sean pojos (y por lo tanto usen el constructor vacío), aquí esto no supone un problema y es Spring quien se adapta y nos da la libertad de trabajar como queremos. Por otro lado, obligamos a que, cuando se crea un objeto, se lo haga de la forma adecuada (con todas sus dependencias creadas si o si).
Por otro lado, inyectar por constructor puede hacer engorrosa la herencia y si el bean tiene muchas dependencias se vuelve cada vez más complicado.
Particularmente prefiero inyectar por setter, pero es bueno tener ambas posibilidades.
Inyectar beans exclusivos.
Hay situaciones donde un bean debería ser una dependencia de otro de manera exclusiva. El problema del archivo xml de Spring es que una vez declarado, el bean puede ser dependencia de cualquiera. Por ejemplo:
Hasta aquí nada sobresaliente, simplemente hemos agregado a la clase Persona un objeto Documento y lo hemos vinculado para que funcionen en conjunto.


Pero hay un pequeño problema. ¿Que pasa si agregamos lo siguiente en el xml?
Leo esta usando el documento de Liz!! Eso no es correcto y, por ello, Spring permite crear beans exclusivos de la siguiente manera:
Hay que tener mucho cuidado al crear objetos de este tipo ya que estaremos impidiendo la reutilización del código.
Scope de un bean.
Por defecto, todos los beans de Spring son Singletons. Si no se conoce dicho patrón se puede leer en http://migranitodejava.blogspot.com/2011/05/singleton.html
Spring sólo crea una única instancia de cada objeto en su contenedor y luego la reutiliza. Todos sabemos que en ciertos casos esto no es conveniente, por lo que nos da la opción de cambiarlo. Para ello, en la etiqueta bean hay un atributo llamado scope que puede tomar los siguientes valores:
Ojo si usan una versión anterior a Spring 2 que esto se trata de manera diferente.
Como se habrán dado cuenta, este singleton de Spring tiene una particularidad: no es realmente un Singleton. Es decir, Spring nos asegura que nos devolverá una única instancia pero nada impide que haga un new Object().
Muchas veces nosotros necesitamos controlar el Singleton para evitar problemas. Para ello Spring nos brinda una solución:
 Y en el xml definimos cual es el método encargado de crear el bean:
Y en el xml definimos cual es el método encargado de crear el bean:

De esta forma, es posible adaptar a Spring para que instancie los objetos como nosotros le digamos. Este ya si es un Singleton propiamente dicho.
Autoconexión.
Vimos que es posible conectar las propiedades mediante un constructor o los métodos setters. Hasta aquí se hizo de manera explícita en el archivo xml. Pero se puede hacer que Spring resuelva esto por nosotros mediante el atributo autowire de cada bean. Hay 4 tipos de autoconexión:

Y en el xml:

Autoconexión por defecto.
Por defecto, los beans no se conectan. Pero esto se puede cambiar en la etiqueta beans:
De esta forma, le estamos diciendo a Spring que conecte por byName por defecto, lo que se puede sobreescribir en cualquier etiqueta bean.
Colecciones.
Voy a asumir que ya todos conocen el concepto de List, Set, Map y las colecciones más importantes de Java, como por ejemplo Properties. Así que iré directamente a un ejemplo integrador donde se mostrará como configurar Spring para cada tipo de colección. De todas maneras, es muy intuitivo entenderlo.
List, set y arrays funcionan de manera similar. Cuando son array o list simplemente debo confgurar el xml de la siguiente manera (si son sets, solo hay que cambiar <list> por <set>):
Tanto en la clave como en el valor es posible referenciar a otros beans en lugar de poner Strings. Para ello, en vez de key debemos colocar key-ref donde haremos referencia hacia el id de otro bean. Lo mismo ocurre en el valor: en vez de value debemos colocar value-ref.
En cuanto a los properties (clase java.util.Properties) se hace de la siguiente manera:
Herencia entre beans.
Es posible utilizar herencia dentro de los beans declarados en el xml de Spring, lo cual nos puede permitir que nuestro archivo se reduzca en cuanto a la cantidad de líneas que tenemos que escribir. Para ello, el tag bean posee 2 atributos que, hasta ahora, no hemos utilizado. Estos son:



Y el xml era así:
Ahora vamos a hacer un pequeño cambio en el xml y lo vamos a dejar así:
Creando Beans.
En Spring hay diversas formas de crear un bean. En el ejemplo de la introducción a Spring vimos una opción donde colocábamos la ruta del xml de configuración:
ApplicationContext respuesta =
new FileSystemXmlApplicationContext("C:/Users/max/eclipse workspace/spring.xml");
Esta forma de crear beans esta bien para un ejemplo o aplicaciones muy chicas, pero es poco práctico para el resto de los casos. Spring nos brinda formas alternativas a FileSystemXmlApplicationContext y las más utilizadas son:
ClassPathXmlApplicationContext: busca el xml en el classpath, para mi gusto es la mejor opción.
XmlWebApplicationContext: el xml se encuentra en un contexto de una aplicación web.
Ciclo de vida de un bean.
En Spring la vida de un objeto difiere de la forma tradicional: existen más oportunidades para aprovechar en la creación o destrucción de un bean. Las distintas etapas son:
- Instanciación del bean.
- Inyección de propiedades.
- Nombre del bean: si el bean implementa BeanNameAware, Spring le pasa el id en el método setBeanName(). De esta forma, sabe cual es su id según el xml de Spring.
- Contexto: si el bean implementa ApplicationContextAware, Spring llama al método setApplicationContext() y le pasa el contexto como parámetro.
- Post proccessor: si hay un BeanPostProccessor, Spring llama al método postProccessBeforeInitialization().
- Inicializar bean: si implementa InitializingBean, se llama a afterPropertiesSet().
- Post proccessor (de nuevo!): si hay un BeanPostProccessor, Spring también llama al método postProccessAfterInitialization().
- El bean esta listo para ser utilizado!
- Destrucción del bean: si implmenta DisposableBean se llama a destroy().
Y agregamos lo siguiente al xml:
<bean id="persona" class="ejemplo.Persona" >
<property name="nombre" value="Maxi"/>
</bean>
Inyección por constructores.
Es posible instanciar objetos con un constructor distinto al vacío. Para ello existe un tag llamado <constructor-arg> que posee dos atributos importantes: ref y value. Por ejemplo, si tenemos un constructor que recibe un int podriamos hacer lo siguiente:
<constructor-arg value=”100” />
Pero si se recibe un objeto compuesto se deberá usar el atributo ref que hace referencia a otro bean de Spring y se lo llama por su id:
<constructor-arg ref=”persona” />
Veamos un ejemplo:
<bean id="persona" class="ejemplo.Persona" >
<constructor-arg value="100" />
<constructor-arg value="Perez" />
<property name="nombre" value="Maxi"/>
</bean>
Entonces …¿conviene inyectar por constructor o por setter?
Es muy útil la inyección por constructor por varios motivos. Primero, a diferencia de la mayoría de frameworks que nos obligan a que casi todas nuestras clases sean pojos (y por lo tanto usen el constructor vacío), aquí esto no supone un problema y es Spring quien se adapta y nos da la libertad de trabajar como queremos. Por otro lado, obligamos a que, cuando se crea un objeto, se lo haga de la forma adecuada (con todas sus dependencias creadas si o si).
Por otro lado, inyectar por constructor puede hacer engorrosa la herencia y si el bean tiene muchas dependencias se vuelve cada vez más complicado.
Particularmente prefiero inyectar por setter, pero es bueno tener ambas posibilidades.
Inyectar beans exclusivos.
Hay situaciones donde un bean debería ser una dependencia de otro de manera exclusiva. El problema del archivo xml de Spring es que una vez declarado, el bean puede ser dependencia de cualquiera. Por ejemplo:
<bean id="liz" class="ejemplo.Persona" >
<constructor-arg value="3" />
<constructor-arg value="Juarez" />
<property name="nombre" value="Liz"/>
<property name="documento" ref="documentoLiz"/>
</bean>
<bean id="documentoLiz" class="ejemplo.Documento" >
<property name="tipo" value="DNI"/>
<property name="numero" value="123456789"/>
</bean>
Hasta aquí nada sobresaliente, simplemente hemos agregado a la clase Persona un objeto Documento y lo hemos vinculado para que funcionen en conjunto.
Pero hay un pequeño problema. ¿Que pasa si agregamos lo siguiente en el xml?
<bean id="leo" class="ejemplo.Persona" >
<constructor-arg value="30" />
<constructor-arg value="Gonzalez" />
<property name="nombre" value="Leo"/>
<property name="documento" ref="documentoLiz"/>
</bean>
Leo esta usando el documento de Liz!! Eso no es correcto y, por ello, Spring permite crear beans exclusivos de la siguiente manera:
<bean id="liz" class="ejemplo.Persona" >
<constructor-arg value="3" />
<constructor-arg value="Juarez" />
<property name="nombre" value="Liz"/>
<property name="documento">
<bean class="ejemplo.Documento" >
<property name="tipo" value="DNI"/>
<property name="numero" value="123456789"/>
</bean>
</property>
</bean>
Observamos que Spring permite definir un bean dentro de una propiedad que no lleva el atributo id y, por lo tanto, no es posible referenciarlo de ninguna manera.Hay que tener mucho cuidado al crear objetos de este tipo ya que estaremos impidiendo la reutilización del código.
Scope de un bean.
Por defecto, todos los beans de Spring son Singletons. Si no se conoce dicho patrón se puede leer en http://migranitodejava.blogspot.com/2011/05/singleton.html
Spring sólo crea una única instancia de cada objeto en su contenedor y luego la reutiliza. Todos sabemos que en ciertos casos esto no es conveniente, por lo que nos da la opción de cambiarlo. Para ello, en la etiqueta bean hay un atributo llamado scope que puede tomar los siguientes valores:
- Singleton: es el valor default e implica una única instancia.
- prototype: se instancia todas las veces que sea necesario.
- request: válido en Spring MVC, donde es instanciado por cada petición HTTP.
- session: válido en Spring MVC, donde es instanciado por cada usuario.
- global-session: válido en Spring MVC, donde es instanciado en una session global HTTP.
Ojo si usan una versión anterior a Spring 2 que esto se trata de manera diferente.
Como se habrán dado cuenta, este singleton de Spring tiene una particularidad: no es realmente un Singleton. Es decir, Spring nos asegura que nos devolverá una única instancia pero nada impide que haga un new Object().
Muchas veces nosotros necesitamos controlar el Singleton para evitar problemas. Para ello Spring nos brinda una solución:
<bean id="fechaUtils" class="calendario.FechaUtils" factory-method="getInstance"/>
De esta forma, es posible adaptar a Spring para que instancie los objetos como nosotros le digamos. Este ya si es un Singleton propiamente dicho.
Autoconexión.
Vimos que es posible conectar las propiedades mediante un constructor o los métodos setters. Hasta aquí se hizo de manera explícita en el archivo xml. Pero se puede hacer que Spring resuelva esto por nosotros mediante el atributo autowire de cada bean. Hay 4 tipos de autoconexión:
- byName: es la más común, ya que conecta por ID (ver el ejemplo). Si no se encuentra un bean correspondiente la propiedad queda sin conectar.
- byType: busca un único bean en el contenedor cuyo tipo sea correspondiente con la propiedad a conectar. Si no se encuentra no conecta, pero si encuentra más de una lanza una UnsatisfiedDependenciException.
- constructor: busca uno o más beans del contenedor que correspondan con los parámetros del constructor del bean a conectar. Si no puede resolverlo lanza una UnsatisfiedDependenciException.
- autodetect: intenta primero conectar por constructor y luego byType.
Y en el xml:
<bean id="persona" class="ejemplo.Persona" scope="prototype" autowire="byName">
<constructor-arg value="100" />
<constructor-arg value="Perez" />
<property name="nombre" value="Maxi"/>
</bean>
<bean id="domicilio" class="ejemplo.Domicilio" >
<property name="calle" value="Av. Rivadavia"/>
<property name="numero" value="948"/>
<property name="localidad" value="Bs As"/>
</bean>
Autoconexión por defecto.
Por defecto, los beans no se conectan. Pero esto se puede cambiar en la etiqueta beans:
<beans default-autowire="byName">
...
</beans>De esta forma, le estamos diciendo a Spring que conecte por byName por defecto, lo que se puede sobreescribir en cualquier etiqueta bean.
Colecciones.
Voy a asumir que ya todos conocen el concepto de List, Set, Map y las colecciones más importantes de Java, como por ejemplo Properties. Así que iré directamente a un ejemplo integrador donde se mostrará como configurar Spring para cada tipo de colección. De todas maneras, es muy intuitivo entenderlo.
List, set y arrays funcionan de manera similar. Cuando son array o list simplemente debo confgurar el xml de la siguiente manera (si son sets, solo hay que cambiar <list> por <set>):
<bean id="persona" class="ejemplo.Persona" >
<property name="telefonos">
<list>
<list>
<ref="telefono1">
<ref="telefono2">
<ref="telefono3">
</list>
</property>
</bean>
Y un Map sería:
<map>
<entry key="clave1" value="valor1">
<entry key="clave2" value="valor2">
</map>
En cuanto a los properties (clase java.util.Properties) se hace de la siguiente manera:
<props>
<prop key="clave1" >valor1</prop>
<prop key="clave2">valor2</prop>
</props>
Herencia entre beans.
Es posible utilizar herencia dentro de los beans declarados en el xml de Spring, lo cual nos puede permitir que nuestro archivo se reduzca en cuanto a la cantidad de líneas que tenemos que escribir. Para ello, el tag bean posee 2 atributos que, hasta ahora, no hemos utilizado. Estos son:
- parent: indica quien es el padre (como un extends).
- abstract: indica si es un bean abstracto que me sirve solo como modelo pero que nunca se va a instanciar. Toma valores true o false.
<bean id="empleado" class="ejemplo.Empleado" abstract="true">
<property name="domicilioLaboral" value="Av. Rivadavia 123"/>
<property name="telefonoLaboral" value="49876648"/>
</bean>
<property name="domicilioLaboral" value="Av. Rivadavia 123"/>
<property name="telefonoLaboral" value="49876648"/>
</bean>
Luego, cada vez que quiera crear un empleado solo debo hacer lo siguiente:
<bean id="juan" parent="empleado"/>
Si un empleado no tiene, por ejemplo, ese domicilio laboral, entonces se lo puede sobreescribir:
<bean id="sergio" parent="empleado">
<property name="domicilioLaboral" value="Av. Cordoba 233"/>
</bean>
Y el xml era así:
<bean id="saludoImpl" class="saludo.SaludoImpl">
<property name="valor" value="Hola mundo!"/>
</bean>
<bean id="alumno" class="saludo.Alumno" >
<property name="saludo" ref="saludoImpl"/>
</bean>
Ahora vamos a hacer un pequeño cambio en el xml y lo vamos a dejar así:
<bean id="saludoImpl" class="saludo.SaludoImpl">
<property name="valor" value="Hola mundo!"/>
<replaced-method name="saluda" replacer="saludoAlternativo"/>
</bean>
<property name="valor" value="Hola mundo!"/>
<replaced-method name="saluda" replacer="saludoAlternativo"/>
</bean>
<bean id="saludoAlternativo" class="saludo.SaludoAlternativo"/>
Y realizamos la implementación SaludoAlternativo:

De esta forma se sustituye lo que devuelve el método por la implementación de tiempoImpl. En la practica la sustitución por método no se suele utilizar demasiado ya que no son demasiados los casos donde se puede aplicar (¿para que voy a hacer un método que despues lo voy a cambiar no?), pero es bueno saber que existe.
Estas son las características principales del Core de Spring. Cuando tenga tiempo y ganas escribiré un post sobre Spring AOP.
Y realizamos la implementación SaludoAlternativo:
Como se imaginarán hemos cambiado el "Hola mundo" por algo más actual. =)
2) Sustitución por getter: permite que los métodos sean sustituidos en tiempo de ejecución con nuevas implementaciones. En realidad es un caso especial de la sustitución anterior. Se suele utilizar en casos de métodos abstractos, aunque no es obligatorio.
Vamos a porner un ejemplo sencillo. Imaginemos que una clase llamada Reloj posee el siguiente método:
public abstract Tiempo getTiempo();
En el xml se podría escribir:
<bean id="reloj" class="ejemplo.Reloj">
<lookup-method name="getTiempo" bean="tiempoImpl"/>
</bean>
De esta forma se sustituye lo que devuelve el método por la implementación de tiempoImpl. En la practica la sustitución por método no se suele utilizar demasiado ya que no son demasiados los casos donde se puede aplicar (¿para que voy a hacer un método que despues lo voy a cambiar no?), pero es bueno saber que existe.
Estas son las características principales del Core de Spring. Cuando tenga tiempo y ganas escribiré un post sobre Spring AOP.
Suscribirse a:
Comentarios (Atom)